Using User Reviews to Predict Rating Neural Network
Application of RNN for client review sentiment analysis

In my previous blog post I wrote well-nigh using BeautifulSoup for scraping over two one thousand Flixbus customer reviews and identifying visitor's strengths and weaknesses by performing NLP analysis.
Building upwards on previous story, I decided to use the collected text data to train a Recurrent Neural Network model for predicting customers' sentiment, which proved to be highly efficient scoring 95.93% accuracy on the examination set.
What is sentiment analysis? Wikipedia provides a nice caption:
"… sentiment analysis aims to determine the mental attitude of a speaker, author, or other subject with respect to some topic or the overall contextual polarity or emotional reaction to a document, interaction, or event." - Source
Without whatsoever further ado let's jump into implementation.
Loading and preparing the data
As a starting point, I loaded a csv file containing 1,780 customer reviews in English with the corresponding rating on the scale from ane to 5, where ane is the lowest (negative) and 5 is the highest (positive) rating. Here is a quick glance at the data frame:
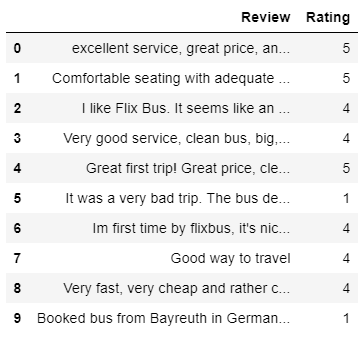
Dandy! Now we have the data to work with. Notwithstanding, as our goal is to predict sentiment — whether review is positive or negative, we take to select appropriate information for this task.
Using Counter function I noticed that we accept quite an unbalanced distribution of reviews per rating:
# Count of reviews per rating
Counter({five: 728, 4: 416, ane: 507, 3: 86, 2: 43}) To balance it out and to ensure a adept representation of the sentiment classes, I decided to keep five star reviews for "positive", while 1 and 2 star reviews for "negative" sentiment. Every bit a result I ended up with a sample size of one,278 reviews in full. Not much, but allow's see what we can become out of it.
Prior to processing the reviews, the sentiment should exist binary encoded with one for positive and 0 for negative sentiment using list comprehension.
data['Sentiment'] = [1 if x > 4 else 0 for 10 in data.Rating] At present we accept a bones prepare and it is fourth dimension to go along with information preprocessing.
Data preprocessing
RNN input requires array data type, therefore, we convert the "Reviews" into the X array and "Sentiment" into the y assortment accordingly.
X, y = (data['Review'].values, data['Sentiment'].values) Text data has to be integer encoded before feeding it into the RNN model. This can exist easily achieved by using basic tools from the Keras library with only a few lines of code:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences tk = Tokenizer(lower = True)
tk.fit_on_texts(X)
X_seq = tk.texts_to_sequences(X)
X_pad = pad_sequences(X_seq, maxlen=100, padding='post')
First, the text should be tokenized past fitting Tokenizer class on the data fix. As you can meet I use "lower = True" statement to convert the text into lowercase to ensure consistency of the data. After, nosotros should map our list of words (tokens) to a list of unique integers for each unique word using texts_to_sequences grade.
As an example, below yous can meet how the original reviews plow into a sequence of integers after applying prepocessing.

Next, we apply pad_sequences class on the list of integers to ensure that all reviews have the same length, which is a very of import step for preparing data for RNN model. Applying this class would either shorten the reviews to 100 integers, or pad them with 0'southward in case they are shorter.

Now, we split the information prepare into training and testing using sklearn's train_test_split and keeping 25% of original data as a hold out set:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X_pad, y, test_size = 0.25, random_state = i)
Furthemore, the preparation ready can be separate into preparation and validation ready:
batch_size = 64
X_train1 = X_train[batch_size:]
y_train1 = y_train[batch_size:] X_valid = X_train[:batch_size]
y_valid = y_train[:batch_size]
It is fourth dimension to build the model and fit it on the training data using Keras:
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dumbo, Dropout vocabulary_size = len(tk.word_counts.keys())+one
max_words = 100 embedding_size = 32
model = Sequential()
model.add(Embedding(vocabulary_size, embedding_size, input_length=max_words))
model.add together(LSTM(200))
model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accurateness'])
As embedding requires the size of the vocabulary and the length of input sequences, we ready vocabulary_size at the number of words in Tokenizer dictionary + i and input_length at 100 (max_words), where value of the latter parameter must exist the aforementioned as for padding(!). Embedding size parameter specifies how many dimensions will be used to stand for each word. Normally i uses the values l, 100 and 300 as an input for this parameter, but while tuning the model value 32 delivered the all-time outcome in this instance.
Next, nosotros add one hidden LSTM layer with 200 retentivity cells. Potentially, calculation more than layers and cells tin can lead to better results.
Finally, we add the output layer with sigmoid activation role to predict a probability of a review being positive.
Afterwards training the model for x epochs, we achieve an accuracy of 98.44% on validation set and 95.93% on test (hold out) set.
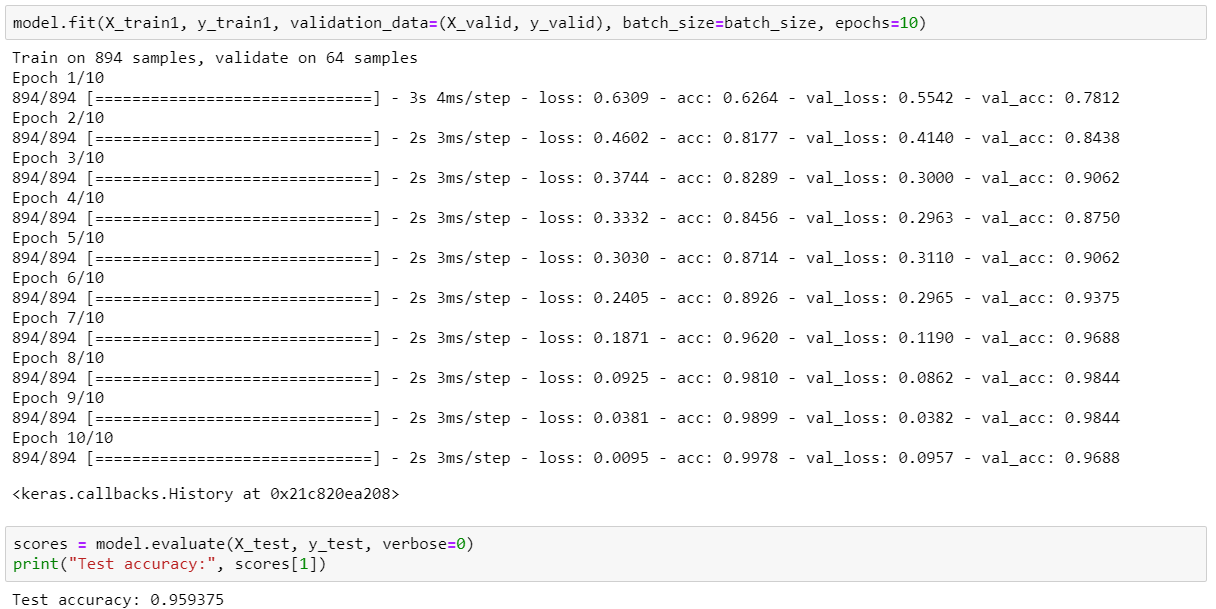

Isn't that awesome? Let's double check to be on a condom side!
Concluding validation
To validate the accuracy of the model further, I additionally scraped 100 latest customer reviews of Flixbus from Trustpilot, which of course where not included in the original data gear up. The newly scraped reviews include 1, iv and 5 star rating reviews with the following count:
# Count of reviews per rating
Counter({1: 83, four: 13, five: 4}) In society to prepare the reviews for prediction, the same preprocessing steps take to be applied on text before passing them into trained model.
# Prepare reviews for check
Check_set = df.Review.values
Check_seq = tk.texts_to_sequences(Check_set)
Check_pad = pad_sequences(Check_seq, maxlen = 100, padding = 'post') # Predict sentiment
check_predict = model.predict_classes(Check_pad, verbose = 0) # Fix data frame
check_df = pd.DataFrame(list(zip(df.Review.values, df.Rating.values, check_predict)), columns = ['Review','Rating','Sentiment'])
check_df.Sentiment = ['Pos' if x == [i] else 'Neg' for 10 in check_df.Sentiment]
check_df
Finally, we get the following result:
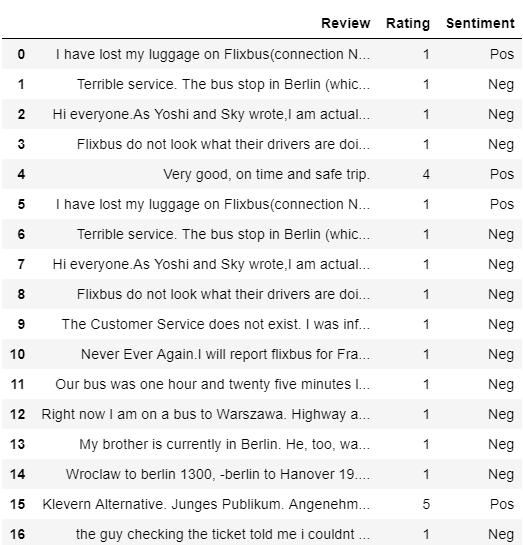
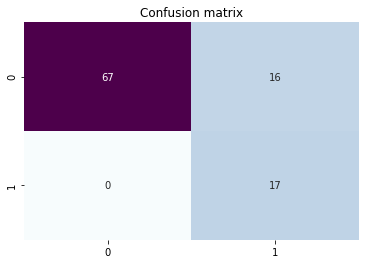
From the screenshot higher up, you can immediately spot some cases of misclassifications. Out of 100 predicted cases, just sixteen reviews with bodily 1 star rating are incorrectly classified equally "Pos" (having positive sentiment). Nonetheless, if we dig deeper, nosotros can come across that the problem is actually not as big as it seems to be:
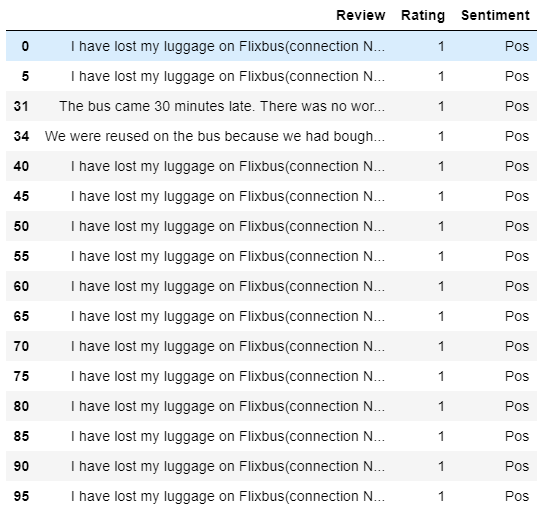
Out of sixteen cases, at that place are merely 3 unique reviews! One review repeats 14 times (non fair 💩). In the mean time, all the residue with rating 4 and five were correctly classified as positive.
That is information technology!
Woohoo! We have successfully trained and validated the performance of RNN for sentiment prediction. Overall, it is a relatively simple and easy job, delivering outstanding results. Promise you lot enjoyed this read and will endeavour to work on your own implementation!
Source: https://towardsdatascience.com/application-of-rnn-for-customer-review-sentiment-analysis-178fa82e9aaf
0 Response to "Using User Reviews to Predict Rating Neural Network"
Post a Comment